The GPU strikes back: Why the GPU will be the premiere compute device for Analytics not just AI
Since their inception, databases had been designed with the notion of compute being a scarce resource. So they organized data in advanced data structures, on disk and in memory, so that when the query comes in, you’re using as little compute resources as possible.
The onset of the GPU as a general compute device marked the beginning of the end for application architectures centered around compute scarcity. So in 2010, Kinetica started thinking about optimizing database design for the idea that compute was an abundant resource. When you have the luxury of being able to do a thousand operations at once, we can be truly focused on leveraging that compute capacity, feeding it as fast as possible, rethinking algorithms to use all the compute power, and simplifying data structures that can continuously grow as data flows in.
This simple idea proved to be incredibly powerful, and the GPU analytics era was born. The promise has always been dramatic: dramatic reductions in data engineering, and hardware footprint, paired with infinite analytical flexibility and performance. However, this vision has not been without some key challenges.
Bandwidth and Memory
Over the past ten years, developers working to pair data analytics with GPU processing had to deal with this central question: How do we get data to the GPU fast enough and how can we keep it there? Remember, the GPU is still an auxiliary processor. That means getting data into the GPU’s native memory requires a transfer over a bus. A bus that has traditionally been considered slow and narrow for the world of big data analytics.
The data-to-compute ratio for AI is way more skewed towards a high level computation for each data element. Analytics workloads have a much lower compute intensity but a much higher I/O intensity. So once you’ve transferred the data into GPU memory, it’s going to blast through whatever analytic operation you’ve set up for it. The tricky part is can you get the right data there or already cached there fast enough. When you do you get paradigm shifting performance, when you don’t you might get a ‘shoulder shrugs’ worth of improvement, or worse.
Now back to that bus: For many years, most GPUs were hamstrung on account of the glacial pace of evolution for the PCI Express (PCIe) system bus. The PCIe 3.0 era seemed to last forever, but in the last few years the dam has finally broken. Enterprise Hardware vendors are adopting the newer PCI standards at a much faster pace and that’s bringing dramatically higher throughput and transfer rates for the GPU.
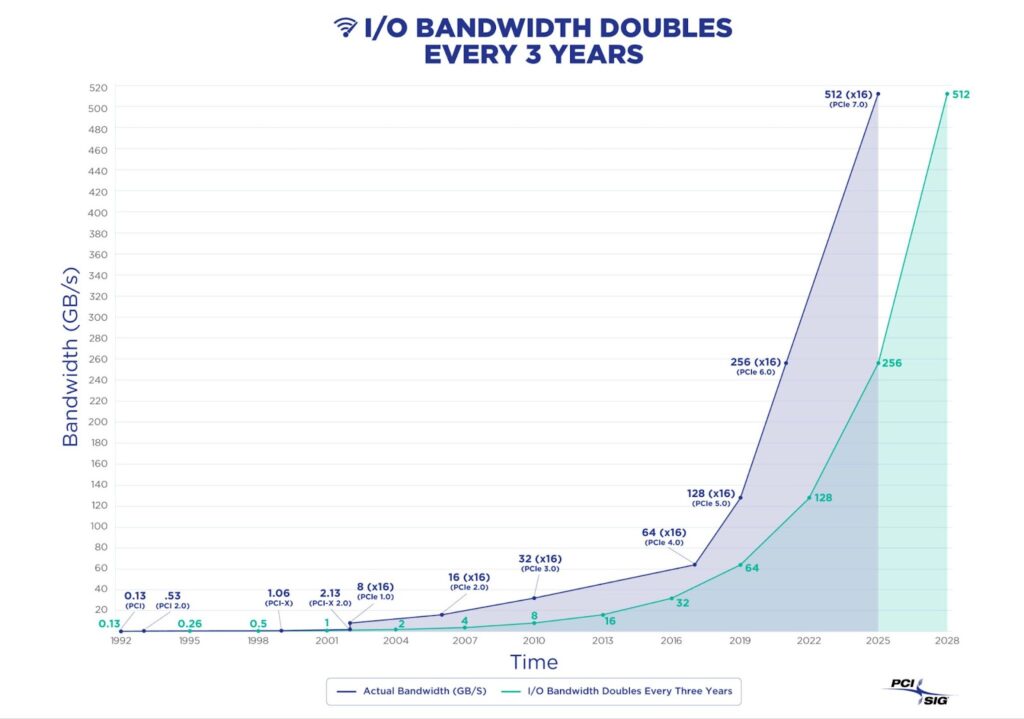
Chart courtesy PCI-SIG.
This hardware trend on its own would be a tremendous harbinger of good times to come for GPU analytics. But when you pair it with another under the radar hardware trend – which is the explosion in VRAM capacity it signals to me an upcoming golden era. Take for instance Nvidia H100 NVL dual-GPU cards — which are geared for staging large language models (LLM) — have 188 GB total VRAM. So these two main analytic bottlenecks for the GPU — getting data to it, and storing data near it — are going away.
A clear path ahead
For analytics, the GPU is going to really start asserting its dominance, the way it already has for AI training. AI training is not so data-heavy, but very compute-heavy. Now with analytics, the GPU has all the necessary components to be able to marry the data with the compute.
The Nvidia A100 and the H100 are the beginnings of this trend. Over the next ten years, it’s going to get more pronounced. The buses are getting faster, and the amount of VRAM is growing to become on-par with the amount of system DRAM. The GPU today is akin to the CPU, the Pentium processor of the ‘90s. It is the premier compute device for the next 15 years. So you’re either able to leverage that, or not.
Making Sense of Sensor Data
