Kinetica, the GPU-powered RAG Engine for Data Copilots, Integrates with NVIDIA NIM
Kinetica, the GPU-powered RAG (Retrieval Augmented Generation) engine, is now integrating deeply with NVIDIA Inference Microservices for embedding generation and LLM inference. This integration allows users to invoke embedding and inferencing models provided by NIM directly within Kinetica, simplifying the development of production-ready generative AI applications that can converse with and extract insights from enterprise data.
NIM packages AI services into containers, facilitating their deployment across various infrastructures while giving enterprises full control over their data and security. By combining these services with Kinetica’s robust compute and vector search capabilities, developers can easily build data copilots that meet rigorous performance and security requirements. The queries below show how you can connect Kinetica to NIM with just a few SQL statements.
-- Create the credentials for connecting to NIM
CREATE CREDENTIALS schema.my_creds
TYPE = ‘NVIDIA_NIM’
API_KEY = ‘<key>’
ORG_ID = ‘<org>’
-- Register an embedding model
CREATE REMOTE MODEL schema.nim_nvidia_qa4
OPTIONS
(
NAME = ’nvidia/embed-qa-4’
CREDENTIALS = schema.my_creds
);
-- Stream embeddings generated by the embedding model into a view in Kinetica
CREATE MATERIALIZED VIEW real_time_embeddings AS
(
SELECT *
FROM GENERATE_EMBEDDINGS
(
TABLE => ‘schema.my_input_table’
MODEL_NAME => ‘schema.my_embed_model’
INPUT_COLUMN_NAMES => ‘text_chunk’,
OUTPUT_COLUMN_NAME => ‘vector_embed_from_NIM’
)
)
REFRESH ON CHANGEA cybersecurity chatbot
We are developing a cybersecurity chatbot using this stack. The chatbot processes two types of sources:
- Data Sources: High-velocity network traffic data and various forms of cyber threat detection data.
- Documents: Information on different types of attacks, network protocols, and indicators of atypical usage.
Given a user prompt, the chatbot interfaces with tabular data sources and text-based knowledge from documents to provide an appropriate response. The diagram below outlines the architecture of the solution. The diagram below outlines the architecture and information workflow of the solution.
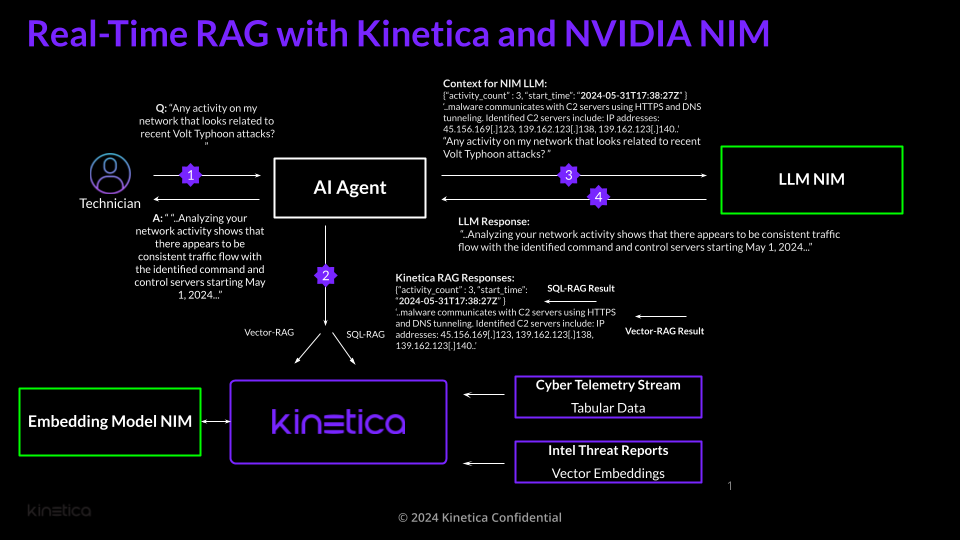
In this scenario, the user interacts with a supervisor agent which is powered by a LLM NIM to search for suspicious activity related to a recent cyberattack. Kinetica is automatically also interfacing with NIM based embedding generation models as documents are inserted into the database to make vector embedding of threat intelligence reports.
Step 1: The user asks the AI Agent “Any activity on my network that looks related to recent Volt Typhoon attacks?” Based on the prompt, the supervisor agent selects the appropriate tool from its toolkit of fine-tuned LLMs.
Step 2: For this prompt, Kinetica first performs Vector search RAG to search recent intel threat reports for relevant IP addresses. Kinetica returns the following result:
‘..malware communicates with C2 servers using HTTPS and DNS tunneling. Identified C2 servers include: IP addresses: 45.156.169[.]123, 139.162.123[.]138, 139.162.123[.]140..’This context, including the IP addresses, is then used by Kinetica in a subsequent SQL-RAG query to search the netflow logs for any related activity. Three recent incidents are found:
{“activity_count” : 3, “start_time”: “2024-05-31T17:38:27Z” }
Step 3: The results from Kinetica are provided to the LLM NIM, along with the original prompt (“Any activity on my network…”) for summarization. Context for main reasoning LLM NIM now contains:
{“activity_count” : 3, “start_time”: “2024-05-31T17:38:27Z” }
‘..malware communicates with C2 servers using HTTPS and DNS tunneling. Identified C2 servers include: IP addresses: 45.156.169[.]123, 139.162.123[.]138, 139.162.123[.]140..’
“Any activity on my network that looks related to recent Volt Typhoon attacks? ”
Step 4: The summary from the LLM NIM is sent back to the user:
A: “ “..Analyzing your network activity shows that there appears to be consistent traffic flow with the identified command and control servers starting May 1, 2024...”Provided below is a simple python example showing how easy it is to leverage Kinetica and the LLM NIM and Embedding to perform advanced RAG operations for more accurate and insightful reasoning. To access NVIDIA NIMs, we leverage the langchain-nvidia-ai-endpoints package that contains LangChain integrations for chat completion and embedding model endpoints that are hosted as NIMs on NVIDIA API Catalog:
#import necessary libraries
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains.combine_documents import create_stuff_documents_chain
from typing import Dict
from langchain_core.runnables import Runnable, RunnablePassthrough , RunnableSerializable
from langchain_core.messages import HumanMessage
from kinetica.embeddings import KineticaEmbeddings
from langchain_community.vectorstores import Kinetica, KineticaSettings
from langchain_nvidia_ai_endpoints import ChatNVIDIA
# Function for creating a configuration object
def create_config() -> KineticaSettings:
return KineticaSettings(host=HOST, username=USERNAME, password=PASSWORD)
# Establishing a connection to Kinetica and the Embedding model NIM
connection: KineticaSettings = create_config()
embeddings: KineticaEmbeddings = KineticaEmbeddings()
# Creating a Kinetica object
db: Kinetica = Kinetica(config=create_config(), embedding_function=embeddings, collection_name="cyber_netflow_and_intel_reports")
# Creating a Kinetica retriever for SQL and Vector similarity search
retriever = db.as_retriever()
# System template for how RAG responses populate main reasoning LLM context.
# Note the two entries, one for Vector and one for SQL
SYSTEM_TEMPLATE: str = '''Answer the user's questions based on the below context. If the context doesn't contain any relevant information to the question, don't make something up and just say "I don't know":
<context>
{context}
</context>'''
# Creating the question answering prompt template
question_answering_prompt: ChatPromptTemplate = ChatPromptTemplate.from_messages([
(
"system",
SYSTEM_TEMPLATE,
),
MessagesPlaceholder(variable_name="messages"),
])
# Create the LLM NIM and the document chain
llm: ChatNVIDIA = ChatNVIDIA(nvapi_key=nvapi_key, model="meta/llama3-70b-instruct")
document_chain: Runnable[dict[str, Any], Any] = create_stuff_documents_chain(llm, question_answering_prompt)
# Function to parse retriever output and prepare context text for main reasoning LLM
def parse_retriever_output(params: Dict[str, Any]) -> Dict[str, Any]:
return params["messages"][-1].content
# Creating a retrieval chain
retrieval_chain: RunnableSerializable = RunnablePassthrough.assign(
context=parse_retriever_output | retriever,
).assign(
answer=document_chain,
)
# Question to send to the retrieval chain
question: str = "What can you tell me about Volt Typhoon in terms of the suspected actors and indicators of compromise based on my network activity?"
# Generate an answer
response = retrieval_chain.invoke({
"messages": [HumanMessage(content=question)],
})
print(response["answer"])
Output based on Real-time network activity and intelligence reports using Kinetica real-time RAG and NVIDIA Inference Microservices
**SUSPICIOUS ACTIVITY DETECTED:**
Analyzing your network activity shows that there appears to be consistent traffic flow with the identified command and control servers starting May 1, 2024.
Here's what's known about the suspected actors and indicators of compromise that match your network activity:
**Suspected Actors:**
* The Volt Typhoon campaign is attributed to a Chinese advanced persistent threat (APT) group, also known as APT10 or Stone Panda.
**Matching Indicators of Compromise (IOCs):**
**Command and Control (C2) Servers:** The malware communicates with C2 servers using HTTPS and DNS tunneling. Identified C2 servers include:
+ IP addresses: 45.156.169[.]123, 139.162.123[.]138, 139.162.123[.]140
+ Domains: techsupport[.]online, softwareupdates[.].space, windowsdefender[.]pro
Kinetica’s RAG engine can complete the analytic and vector search tasks against datasets that represent up to the second network activity and intelligence reports and are billions of rows in size. Kinetica leverages its advanced GPU-accelerated engine to complete these queries in under a second. The integration with NVIDIA Inference Microservices for embedding generation and LLM inference is a critical part of this stack since it makes it easy to couple our low latency compute with containerized inferencing and embedding generation services that are secure, performant and enterprise ready. This enables us to build more sophisticated and responsive AI applications that can leverage large enterprise relational data and document datasets for next level accuracy and insight.
Talk is the future
Harnessing generative AI to extract insights from enterprise data represents a new and exciting opportunity. However, building enterprise-ready AI applications requires a comprehensive ecosystem of robust data capabilities where performance is more important than ever. By combining Kinetica’s compute power with NVIDIA GPUs and the advanced AI services provided by NVIDIA Inference Micro Services, we are paving the way for making natural language the standard for interfacing with enterprise data.
Try Kinetica now, or contact us to learn more.
Making Sense of Sensor Data
