Gen. AI Needs a Real-time Multimodal Retrieval Engine
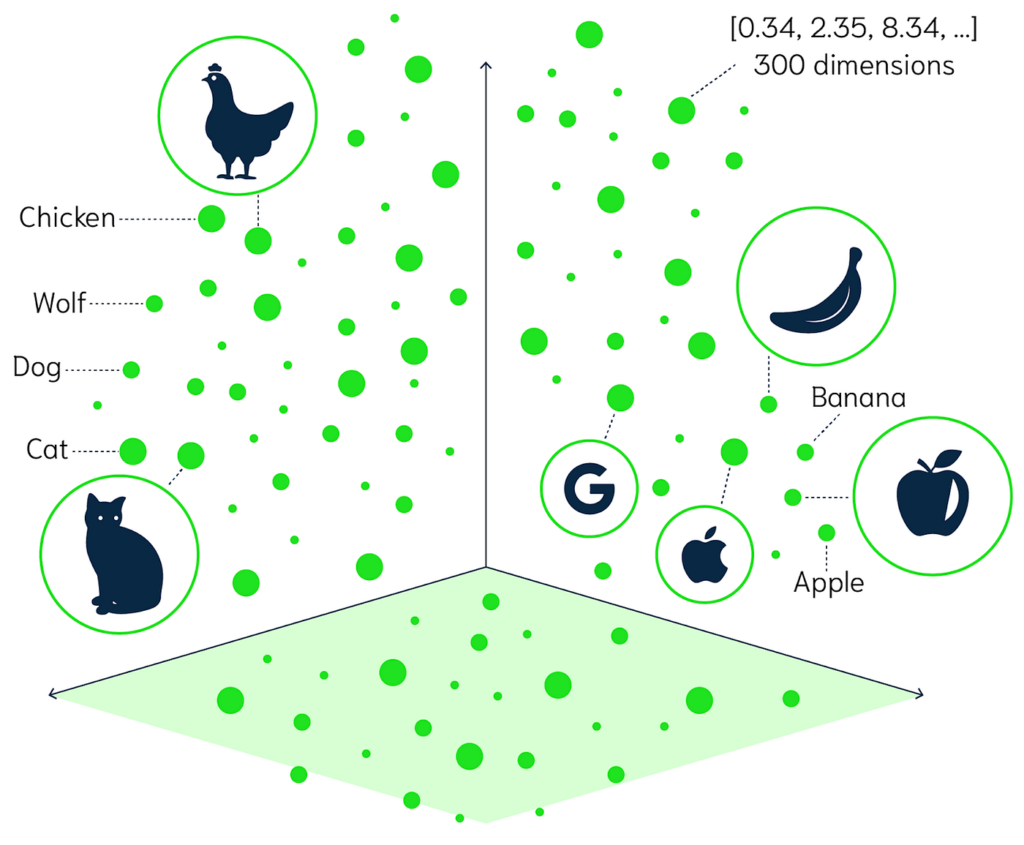
Until recently, pure vector databases like Pinecone, Milvus, and Zilliz were all the rage. These databases emerged to meet a critical need: Large Language Models (LLMs) often require information beyond their training data to answer user questions accurately. This process, known as Retrieval Augmented Generation (RAG), addresses that need by fetching relevant text based information using a vector similarity search.
RAG powers applications like ChatGPT, enabling them to act on information beyond their training, such as summarizing news and answering questions about private documents. By storing and retrieving relevant information to augment an LLM’s knowledge, vector databases played a crucial role in the first phase of Generative AI, facilitating the adoption of tools like ChatGPT.
So why are vector databases being replaced???

While some vector databases will continue to provide value, they are increasingly being replaced by a new breed of multimodal retrieval engines that offer more than just vector search. This shift is driven by the limitations of vector databases in two critical areas:
1. Inability to Retrieve Information from Real-Time Sources at Scale
Consider an AI chat application designed to help customers resolve issues in real-time. For this application to be valuable, it must reference information from real-time sources, such as notes on the customer’s problem, similar incidents reported by other customers, and current backend system logs that might explain why these issues are occurring. This requires the retrieval engine to process millions of real-time records in seconds.
However, such AI chatbots don’t exist today because most databases, including those specializing in vector data, must undergo a time-consuming indexing process when inserting new data. This indexing process clusters similar data together, making retrieval tasks easier. Depending on the database and data scale, indexing can take several minutes to hours, preventing AI applications from accessing the necessary insights to resolve issues in real time. As a result, users often end up resorting to the all-too-familiar refrain when dealing with bots: “Talk to a representative.”

2. Inability to retrieve information from tabular data
Most insights needed to answer business questions are represented in tabular data rather than text. However, vector search only works with text-based sources. As conversational AI expands into enterprise use cases, it will increasingly need to draw referential information from tabular data.

This requires a retrieval engine capable of executing ad-hoc analytics on large enterprise data to extract relevant insights. Very few databases can perform this function effectively.
🫵 You Need a Real-time Retrieval Engine
Act on real-time data instantly
To keep pace with the demands of generative AI, a retrieval engine must ingest and act on real-time data with minimal delay. Traditional databases reliant on extensive indexing can’t react quickly enough. Instead, a future-proof retrieval engine should be capable of loading millions of real-time records per second, making this data immediately available for both analytics and search. This capability must extend to both tabular data and vector embeddings.
Execute Complex Multimodal Retrieval in Seconds
A defining characteristic of generative AI powered apps is the ad-hoc nature of the conversation. It is impossible to predict the types of questions that a user might pose. As a result sophisticated applications require a retrieval engine that can do many things fast. This includes vector search, but more importantly, it includes the ability to draw analytic insights from real-time and historical data.
To answer user questions a retrieval engine should seamlessly execute complex multimodal analytics in real-time, drawing insights from diverse data types—spatial, time series, graph data, and vector embeddings—without any pre-preparation. And since it is hard to predict the direction that a conversational inquiry of data can take, the database needs to provide wide analytical coverage across various domains time series, spatial, graph etc. along with standard OLAP (aggregations, joins, filters etc.) and vector search.
Do It All Securely At Enterprise Scale
Large enterprises have petabytes of data scattered across thousands of tables and schemas. Conversational modes of inquiry will require an engine that can crunch through vast amounts of data easily. Additionally, for an LLM to generate accurate analytic requests it needs to understand the data that it is trying to draw insights from. So the retrieval engine also has the added responsibility of providing additional semantic context for the data in a way that safeguards enterprise security requirements.
Real-time Multi-modal Retrieval Engines are Hard to Find
Many traditional databases have added support for vector data types. In some cases, this is an improvement over pure vector databases, as they can execute hybrid search queries that enhance the relevance of the returned information by combining vector search with additional analytic filters on metadata.
However, these databases still suffer from the same issues as vector databases. They cannot handle real-time data due to indexing requirements. While they can execute analytics on data, they are too slow to meet the demands of generative AI applications.
As a result, working with databases built for static data and analytics is akin to waiting in a long line before boarding a hypersonic jet. The true potential of speed can only be realized when the retrieval engine can perform vector searches and analytics on real-time data almost instantaneously.
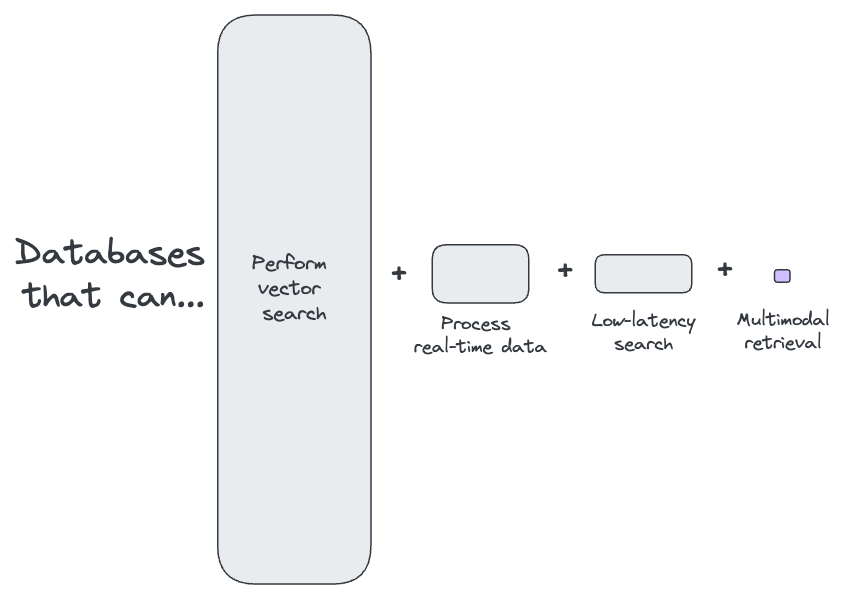
As a final note, the term ‘multimodal’ is often loosely used. Many databases claim to be multimodal simply because they offer standard OLAP functions alongside vector search. However, true multimodal capabilities extend far beyond this. A robust real-time retrieval engine must provide comprehensive analytical coverage across various domains, including:
- Time Series Analysis: Essential for tracking changes and trends over time.
- Spatial Analysis: Crucial for applications involving geographical data and location-based insights.
- Graph Analytics: Necessary for understanding relationships and connections within data.
Try Kinetica
Kinetica is a GPU-accelerated database that is built for real-time workloads. We offer a wide array of analytic functions that are all built from the ground up to harness the massive parallelization offered by GPUs and modern CPUs.
We are the real-time, multimodal retrieval engine that powers conversational AI for enterprise data. Try us out—spinning up an instance of Kinetica on the cloud takes just a few minutes.
Making Sense of Sensor Data
